
My team and I have been to this year’s RoboCon, the annual conference on Robot Framework. This article is a summary of the most relevant talks.
Robot What?
You haven’t heard about Robot Framework so far? In a nutshell, it’s a framework for acceptance testing and acceptance test-driven development (ATDD). It provides a high-level programming language which allows to write test cases in natural language. The Robot Framework (RF) language is based on Python and can thus be easily extended with custom Python libraries. The framework has been around for over ten years now. We first adopted it in 2015 for acceptance testing at Virtual Minds. Since then, it has grown significantly: the RF language, the standard libraries and external libraries allow state-of-the-art test development.
To give you a RF example beyond hello-world, here is a test from our end-to-end test suite. This particular test suite ensures the proper functionality of so-called wallpaper ads. The showcased test focuses on the behaviour of clients that do not accept cookies.
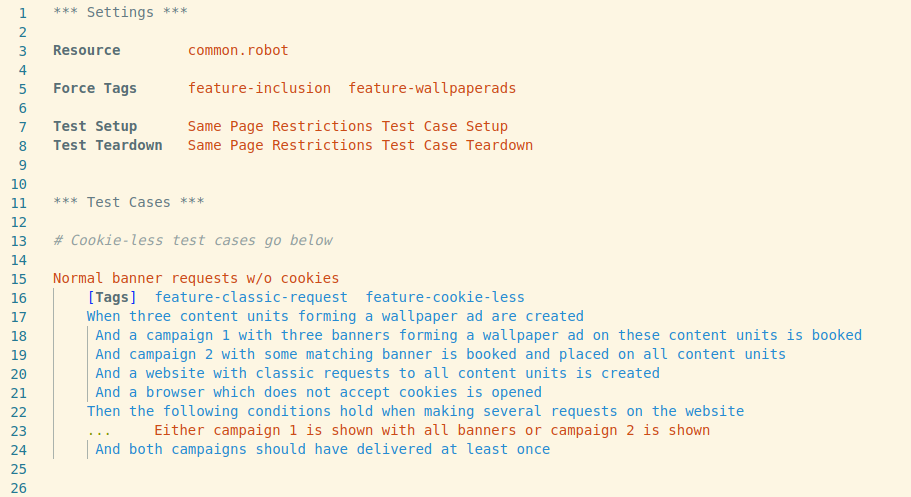
The test creates objects and configures business logic in an isolated test environment, generates a website which includes the respective ad tags, hosts that page on a local web server and finally opens a cookie-less browser. After this setup, the test remote-controls the browser to visit the website. Then it checks certain assertions on the websites elements and structure.
Any testing benefits from a system that uses natural language. Why is that? Because you do not need to learn any programming language to formulate test cases. For instance, think of how a product owner can provide blue prints for acceptance tests. That eases the coordination between product and tech. Or consider the never-ending discussion whether or not the code is documentation enough. In our experience, test cases formulated in natural language are a great way of documenting how things should work—and to find out what exactly is going wrong in case they don’t. Any such testing framework improves the productivity of feature development, maintenance and on-boarding.
What made us choose Robot Framework over alternatives for that tasks? Here are our most important reasons:
- it has a natural-language-first approach
- it is relatively simple to start with
- it is easy to extend if you know Python (we do)
- it has an active community
Now you got an idea what this article is about. So let’s dive into the conference report.
RoboCon 2022
Each year the Robotframework community meets for RoboCon. The current venue was a hybrid conference for two days. Both day 1 and day 2 are available on Youtube. Here, we summarize the most important new stuff we have learnt about and that may benefit our daily work. So what did we bring from the conference?
News and Updates
Changes in Robot Framework 5.0
Robotframework dates back to when people would write acceptance tests using Excel sheets. Table fields used to delimit variables and keywords. Nowadays, nobody wants to program in a table any more. Thus, Robotframework chose whitespace to separate variables, keywords and functions. But that made it impossible to use loop constructs in the usual imperative way, for example as in Python. Boy did we suffer from this! Luckily, this and other quirks from the early days improved a lot over the last releases.
Version 5 continues on that path of adding syntactical sugar as known from other imperative languages with the addition of
- Inline
IFstatements,WHILEloops, and extends existing loop instructions withBREAKandCONTINUEkeywords TRY/EXCEPTstatements are now available in a very similar fashion to Python- The full list of changes is available on github.com/robotframework.
Those changes will lower the entry level for on-boarding new developers to Robotframework.
Toolchain Improvements
Here is a list of new tools that we have learnt about and will experiment with in our tool chain:
- Robotidy is a linter for .robot files. This will be super helpful because we have grown used to have our code formatting done by tools. For instance, we use yapf, black or autopep8 for Python and clang-format for C++
- Robocop goes a step further. It is a static code analyzer. There is one thing interpreted languages like Robotframework and Python suffer from. When you have a typo in your code—say, a misspelled function call—it may take several minutes until the program execution reaches and fails at that point. So you wait until you get the feedback to fix your code. Finding such issues in a static manner can provide much faster feedback. Over the long run, such a static analyzer can safe weeks of development time. This could be huge in terms of productivity.
- Sherlock analyses test code complexity and detecting unused code. That might help to keep your test code base clean and easy to maintain.
- Several talks focused on tools for using Robot Framework for testing against Swagger / Open API. This might prove useful in some forthcoming projects.
- It’s been around for a while now. But many speakers reminded us of how helpful Robotframework language servers for various IDEs are, for instance Visual Studio Code.
Extension Spotlight: Browser Library
Among the many different libraries, the Browser library has seen very active development. We will definitely give it a try because
- It’s shipped with Chrome, Firefox and Safari drivers. That makes manual workarounds with Selenium and headless browser drivers obsolete.
- It automates waiting for page load completion before evaluating expectations on the browser. No more manual polling with
Wait until ...andSleep. - It supports testing with and without Ad-Blockers. Shhhhh!
- It introduces new keywords for doing things like remote-controlling JavaScript execution, testing of tables, …
Robotic Process Automation (RPA)
There are currently many projects adopting Robot Framework for Robotic Process Automation (RPA). RPA is basically combining RF’s expressive language with existing tools for Business Process Modelling. Although this is a reasonable use case we see only limited use for that. Because existing CI/CD tools already make our life quite easy. It might become handy for some recurring troubleshooting tasks, though.
Test Coverage Revisited
Elmar Jürgens introduced an interesting concept in his talk on Test Intelligence for and with the Robot Framework. He was speaking about insights that can be gathered from test coverage metrics. In our experience targeting 100% line coverage is often unfeasible.
But the speaker introduced weakened forms of coverage. The main coverage metric in this talk is defined at function level. A test “covers a function” if the test executes at least one line of code inside the function. Based on this definition of coverage the following problems tackled.
- Optimize execution time for big projects to reach high coverage early on
- Analyse the risk that a series of changesets will introduce a problem which is not caught by tests
For big projects with huge test bases it often takes a lot of time to execute all tests. In cases where it is acceptable to not run all tests, the test execution order can be optimized. By reordering the tests a higher total coverage is reached early on.
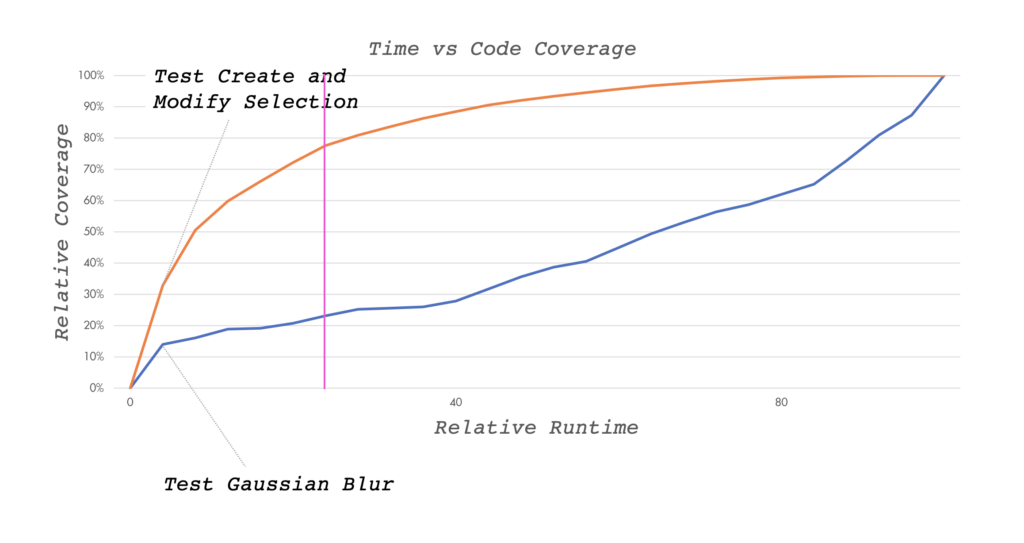
See the graph above how sorting the tests benefits the coverage progression of the test run. That’s an interesting scenario and approach to it. However, it does not apply to us. First, because even our largest test suites run in less than 20 minutes due to isolation and parallelization efforts. Second, we have a policy to tackle flaky tests early on. And finally, we do not accept only partial test runs before merging changesets.
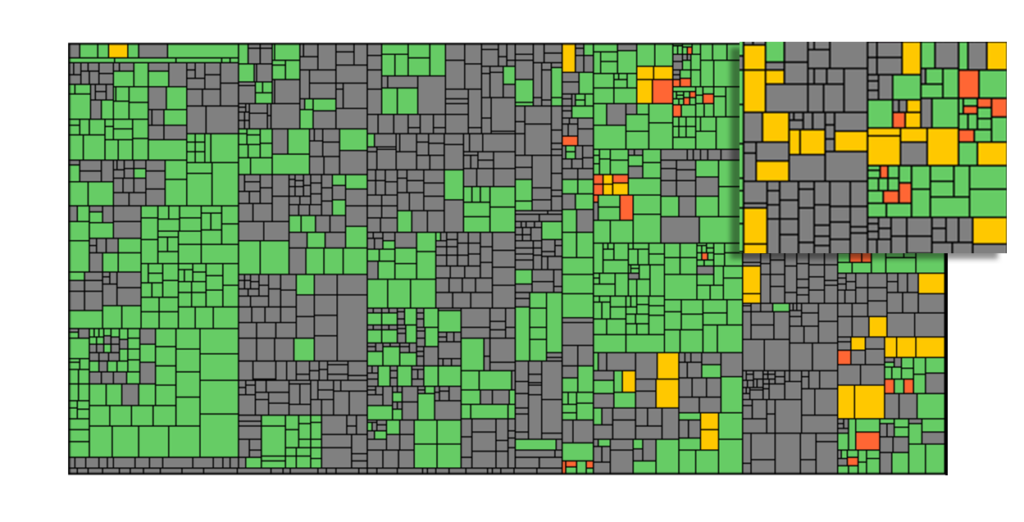
Another interesting approach from this talk are so-called Test Coverage Maps. A box depicts each module, class or function. The size of the box corresponds to the lines of code. The color of each box represents information from changesets and tests execution (untouched, added or modified; and covered or not covered). In the example below,.The resulting graphs give you an idea about how likely a changeset will introduce bugs to your project.
This can become handy in large code bases where you have to accept subpar test coverage due to legacy code.
Top-3 Talks
For the Very First Time
Coming to my personal top 3 of the talks, with Many Kisiriha giving the first of them. I am a former Python-addict nowadays working on different fields. I can’t help to loose the feeling that the whole ecosystem around the language gets revamped once every two years. This talk was a great summary of how to setup and open-source not only a Robotframework library, but any Python library in general. The topics covered in How to Open Source your RF library are available on github.
In a very example-driven way, it summarizes state-of-the-art solution for the following tasks for a Python or Robotframework project:
- How to structure the project
- Python and RF project structure
- How to package it and publish to PyPI
- Use Poetry tool
- How to document keywords
- using Python docstring convention and Python’s libdoc
- How to unittest and acceptance test your library
- Pytest for unittesting
- Python test coverage module
- RF for acceptance tests
- Automate all this using
invoke- invoke tests, invoke libdoc, invoke publish, …
- github actions
We have some candidates for open-sourcing among our libraries. Check out github.com/ADITION for code we have published so far and follow us. Eventually, you may find some RF libraries there.
Using Language Context in RF for Writing Better Tests
Recall the initial example of RF code. It showed a given-when-then test case. This so-called Gherkin style enforces a natural language. It describes the intended behavior of the system, not the implementation. Put short, it describes what, not why. Samuel Montgomery-Blinn takes this to the next level in Using Implicit Context to Create Rich Behavior Driven Keywords. He introduces a technique to allow for natural language references between keywords. When working with references (read: variables) robot code often looks like this:
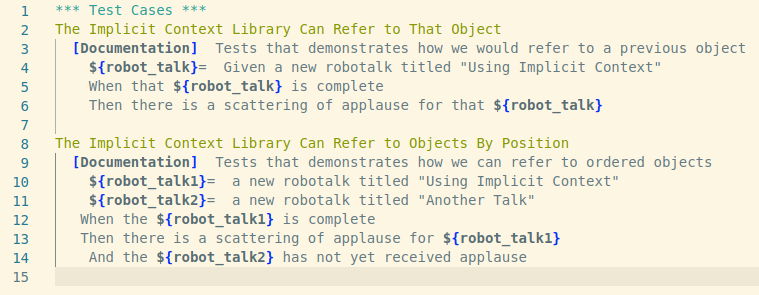
With the techniques presented in the talk, it is possible to have the same test with explicit variables replaced with natural language references. This improves the readability big time. Compare the result yourself:
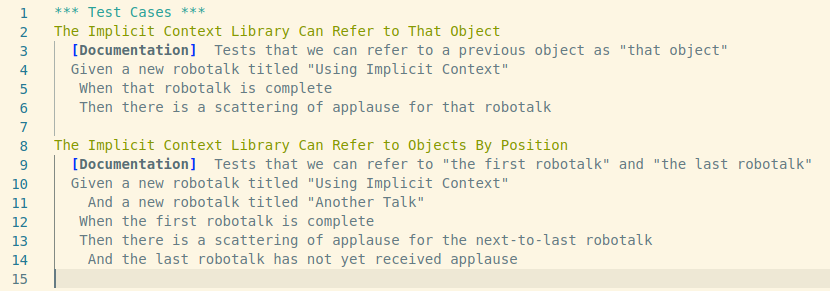
This test has a language which more directly mirrors natural language. And it leverages the power of by being able to refer to ‘previous’ and ‘first’ and ‘that’ objects .
The core idea of the approach is to add objects to a dictionary of context variables. And to translate natural language references into indices (first, second, last become 0, 1, -1). This is invisible to the user, so the technique requires no boilerplate code. The examples as well as the library code are available on github.com/montsamu.
This kind of automatic referencing of objects comes with various problems. For example, variable names may be ambiguous. Or singular and plural forms can be inconsistent. Especially when facing the many exceptions in the English language, this is an interesting field of study. Solving these problems in a reliable and automatic way would set the field for a new generation of programming languages.
That last talk has been one of my favorites. The presented functionality allows for test case formulations in even more natural language. If you are interested in how to write better keywords and tests, checkout also this or that guide.
Keynote: The Neuroscience of Learning, Creativity and Collaboration
Robotframework is on an even higher level of abstraction than Python. The benefit of higher level programming languages is that programs which are closer to human language make it easier to relate the code with actual concepts. And the more natural making that connection feels, the more productive you can be. But how do humans think anyhow?
The conference concluded with the keynote from Katri Saarikivi. In her talk, she gives an overview of the neuroscience of human brains, of how our thinking, learning and empathetic decision making was formed by evolution and what that means for cooperation in a modern work environment.
Katri Saarikivi is a cognitive neuroscientist at the University of Helsinki. Her work examines the neural mechanisms involved in learning, collaboration, empathy and trust, and explores how these mechanisms could be better supported in online environments.
Her keynote is a must see, even if you are not into RF or testing at all.
Summary
The conference brought many new insights and inspiration for our teams. We are looking forward to apply the new concepts to improve the productivity and maintainability of our testing. Although it was a hybrid conference, it has been a great experience. Even with us joining in from remote we were able to connect to some of the speakers for follow-up discussions. We are looking forward for the next venue, maybe then joining in person.